Fine-Tuning vs RAG on AWS Bedrock: When to Use Each
Quick summary: Compare fine-tuning and RAG (retrieval-augmented generation) for customizing LLMs on Bedrock. Cost, latency, and accuracy trade-offs.
Key Takeaways
- Compare fine-tuning and RAG (retrieval-augmented generation) for customizing LLMs on Bedrock
- 10 per 1K input tokens - 100K tokens to fine-tune: ~$10 - Plus inference cost on fine-tuned model: ~$0
- 0001 per 1K tokens - Vector database: $10-50/month - Inference: $0
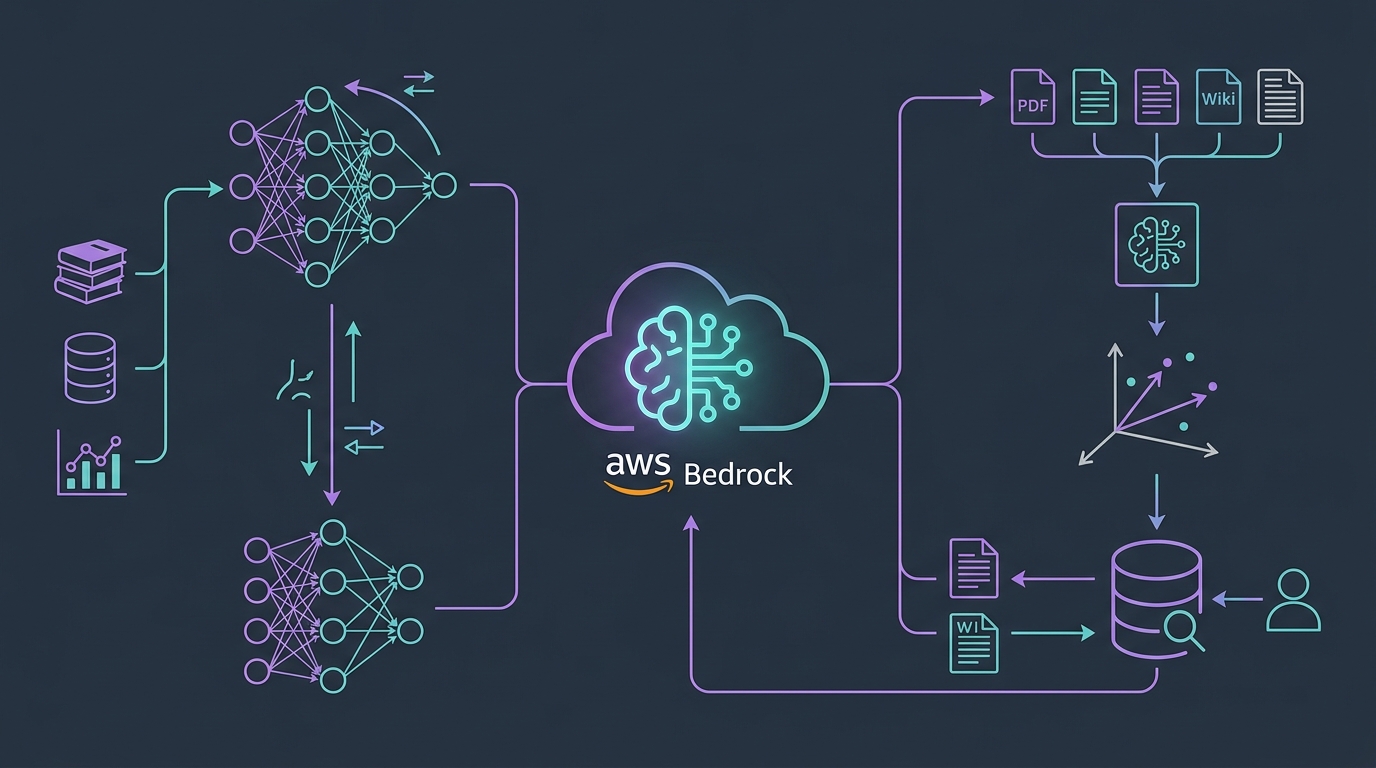
Table of Contents
Fine-Tuning vs RAG: The Core Trade-Off
Fine-Tuning: Train model on your data (permanent change to weights)
- Expensive ($1,000+)
- Takes time (hours)
- Model learns your patterns
- Static knowledge (doesn’t update)
RAG: Retrieve relevant documents, feed to model (external context)
- Cheap ($1-5/month)
- Immediate (no training)
- Always uses fresh data
- Flexible retrieval logic
Fine-Tuning: When & Why
Use Fine-Tuning When:
- Model needs to learn your specific style or domain terminology
- You have 500+ high-quality training examples
- Accuracy improvements justify $1,000+ cost
- You want consistent personality across responses
Example: Customer Support Bot
- Fine-tune on 1,000 customer support conversations
- Model learns your tone, common objections, resolution patterns
- Fine-tuned model gives better responses than base Claude
Fine-Tuning Cost
- Bedrock: $0.10 per 1K input tokens
- 100K tokens to fine-tune: ~$10
- Plus inference cost on fine-tuned model: ~$0.015 per 1K tokens
- Total for small model: ~$50-100/month
RAG: When & Why
Use RAG When:
- You have documents (PDFs, web pages, databases)
- Knowledge changes frequently (quarterly updates)
- You want answers grounded in specific sources
- Cost is critical
Example: Customer Support Bot
- Upload 100 support docs to vector database
- User asks question → retrieve relevant docs → pass to Claude
- Claude answers based on docs
- Update docs without retraining
RAG Cost
- Embeddings: ~$0.0001 per 1K tokens
- Vector database: $10-50/month
- Inference: $0.003 per 1K tokens (cheap, just input+output)
- Total: $20-100/month
Architecture Comparison
Fine-Tuning
Training data → Bedrock fine-tune → Fine-tuned model
↓
User question → ResponseRAG
Documents → Embeddings → Vector DB → Retrieval (top K docs)
↓
User question + docs → Model → ResponseAccuracy & Hallucination
Fine-Tuning
- Model learns to recognize false statements
- Trained on your examples (hopefully high quality)
- More stable responses (learned patterns)
- Risk: overfitting on training data
RAG
- Model references specific documents
- Can cite sources (“According to our docs…”)
- Less hallucination (grounded in real data)
- Risk: retrieves wrong documents
Winner (RAG): RAG is more transparent and verifiable
Knowledge Updates
Fine-Tuning
- Static knowledge (locked at training time)
- New data requires retraining (24+ hours)
- Expensive to keep current
RAG
- Fresh data always (retrieves on each query)
- Update documents in real-time
- No retraining needed
Winner (RAG): RAG handles dynamic knowledge better
Hybrid Approach: Best of Both
Combine fine-tuning + RAG for enterprise applications:
Fine-tune:
- Style & tone (how you write)
- Common reasoning patterns
- Domain terminology
RAG:
- Current product specs
- Customer policies
- Recent pricing
Result: Model responds in your voice, with current facts
Example:
User: "What's our refund policy?"
1. RAG retrieves latest refund policy
2. Fine-tuned model formats in company style
3. Response: professional, accurate, up-to-dateDecision Tree
Do you have 500+ training examples?
├─ Yes → Fine-tuning worth considering
│ └─ Does accuracy improvement justify $1,000+ cost?
│ ├─ Yes → Fine-tune + RAG hybrid
│ └─ No → Just use RAG
└─ No → Use RAG onlyImplementation Timeline
RAG (Quick)
- Day 1: Upload documents, test retrieval
- Week 1: Integrate with application
- Total setup: 3-7 days
Fine-Tuning (Slower)
- Week 1: Prepare 500+ examples
- Week 2: Fine-tune (can take 1-2 hours)
- Week 3: Evaluate & iterate
- Total setup: 2-3 weeks
Real-World Recommendation
Start with RAG for most use cases:
- Cheaper
- Faster to implement
- Easier to debug
- Can update data without retraining
Add Fine-Tuning if RAG performance insufficient after 2-4 weeks:
- You have data showing where RAG fails
- You have budget for $1,000+ investment
- Performance difference is worth it
For most enterprises, RAG + basic prompt engineering beats expensive fine-tuning.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.