palaniappan p 3 min
Fine-Tuning vs RAG on AWS Bedrock: When to Use Each
Compare fine-tuning and RAG (retrieval-augmented generation) for customizing LLMs on Bedrock. Cost, latency, and accuracy trade-offs.
Compare fine-tuning and RAG (retrieval-augmented generation) for customizing LLMs on Bedrock. Cost, latency, and accuracy trade-offs.

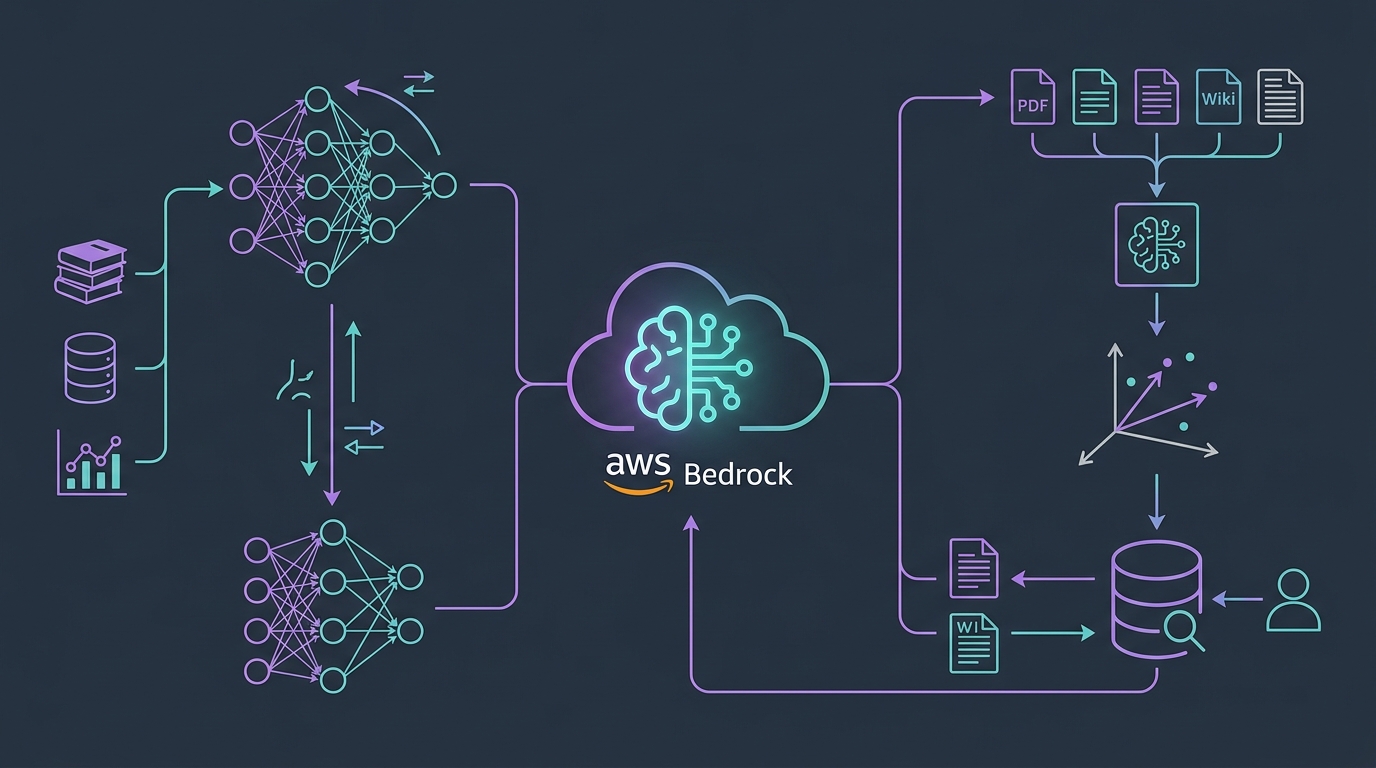
Amazon Bedrock Knowledge Bases automate the RAG (Retrieval-Augmented Generation) pipeline — semantic search, chunking, embedding, and context injection into Claude or other foundation models. This guide covers setup, data ingestion, cost optimization, and production patterns.
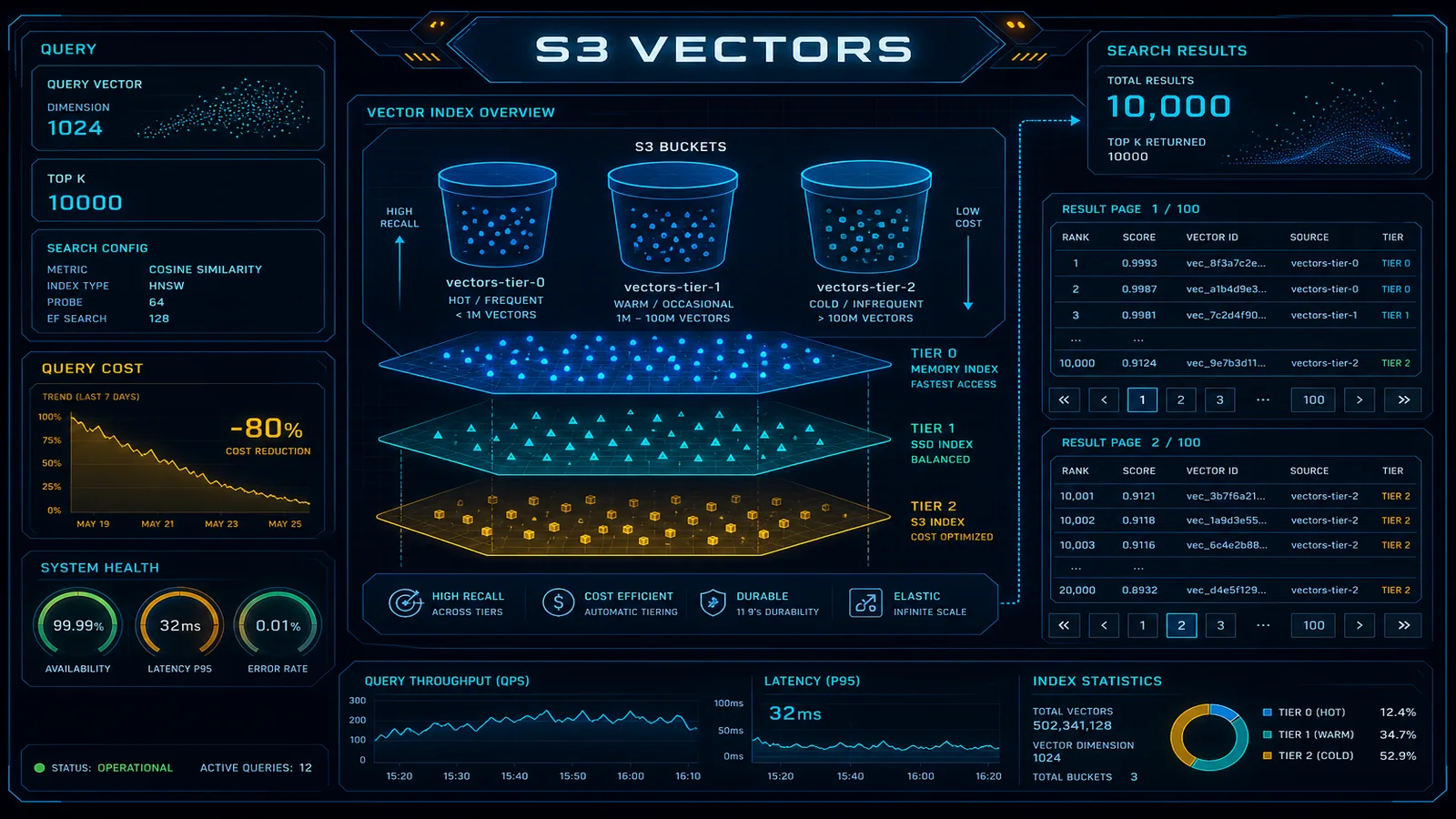
On June 16, 2026, S3 Vectors raised the QueryVectors limit to 10,000 results per query and cut data-processed charges up to 80% on indexes over 10M vectors. Architecture, pagination, and cost comparison vs OpenSearch and MemoryDB.
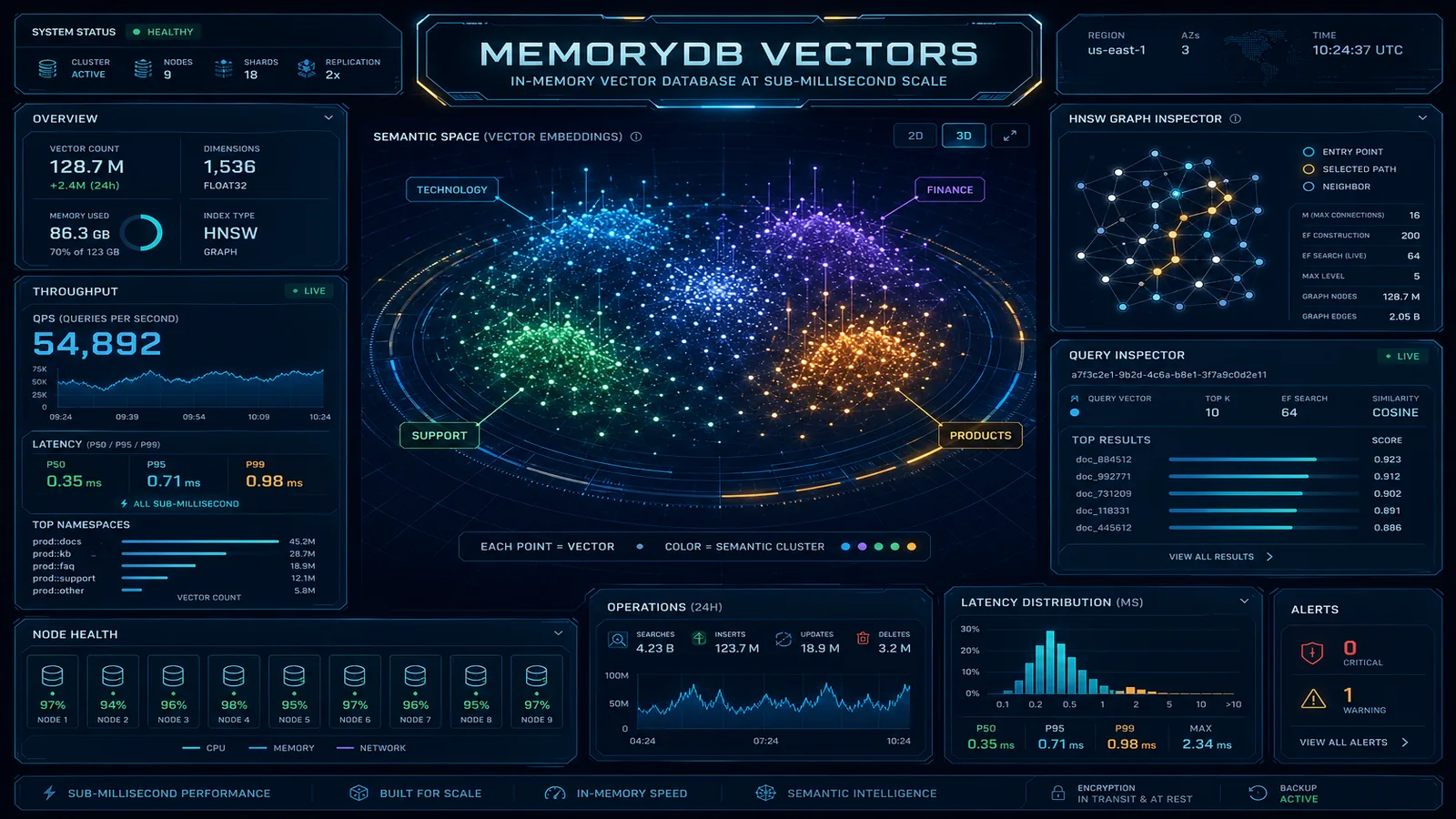
ElastiCache loses your AI chatbot's session memory at every node replacement. MemoryDB doesn't. A decision framework for when to pick MemoryDB over ElastiCache, OpenSearch Serverless, and S3 Vectors for AI workloads — with the latency math and the failure mode that forces the switch.