DevOps & CI/CD
Part 3
palaniappan p 2 min
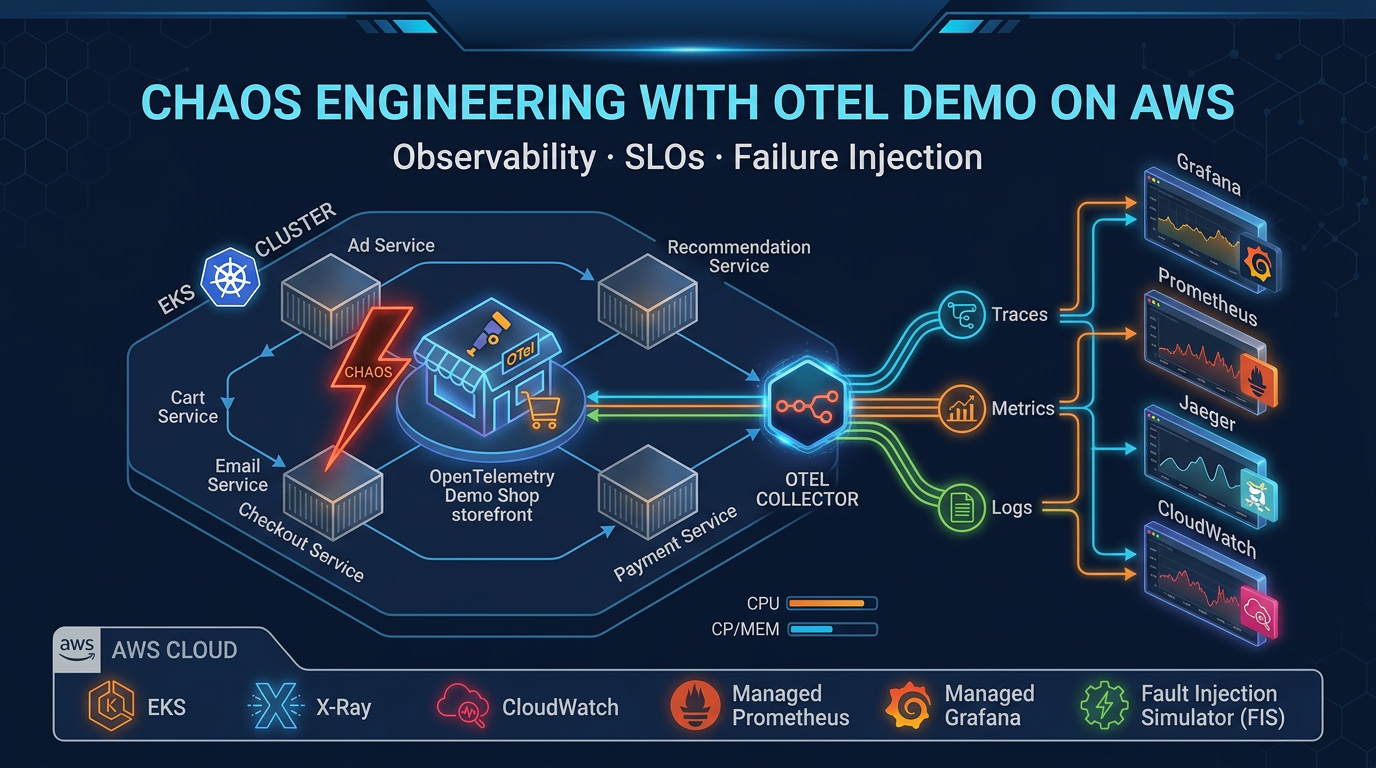
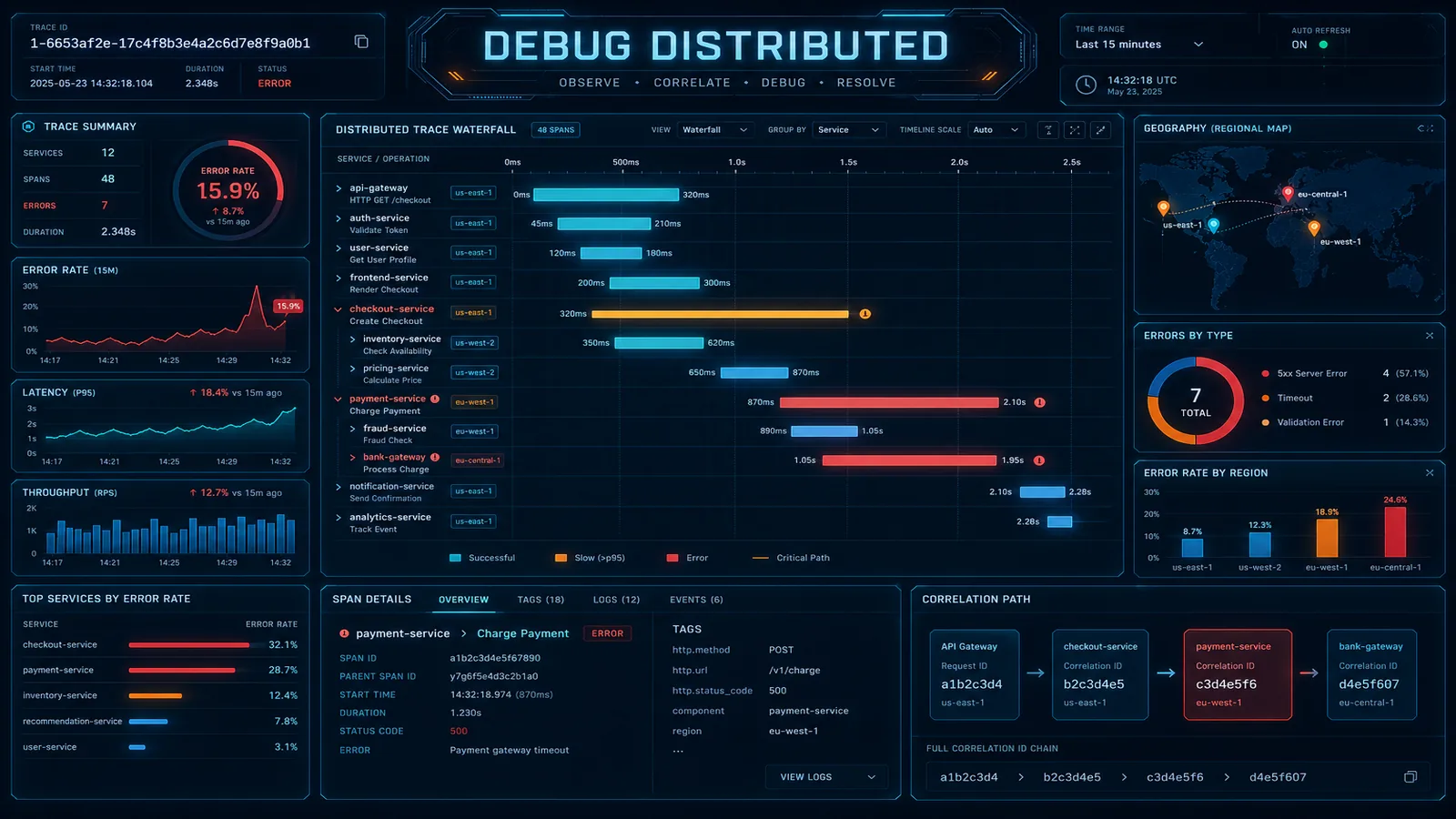
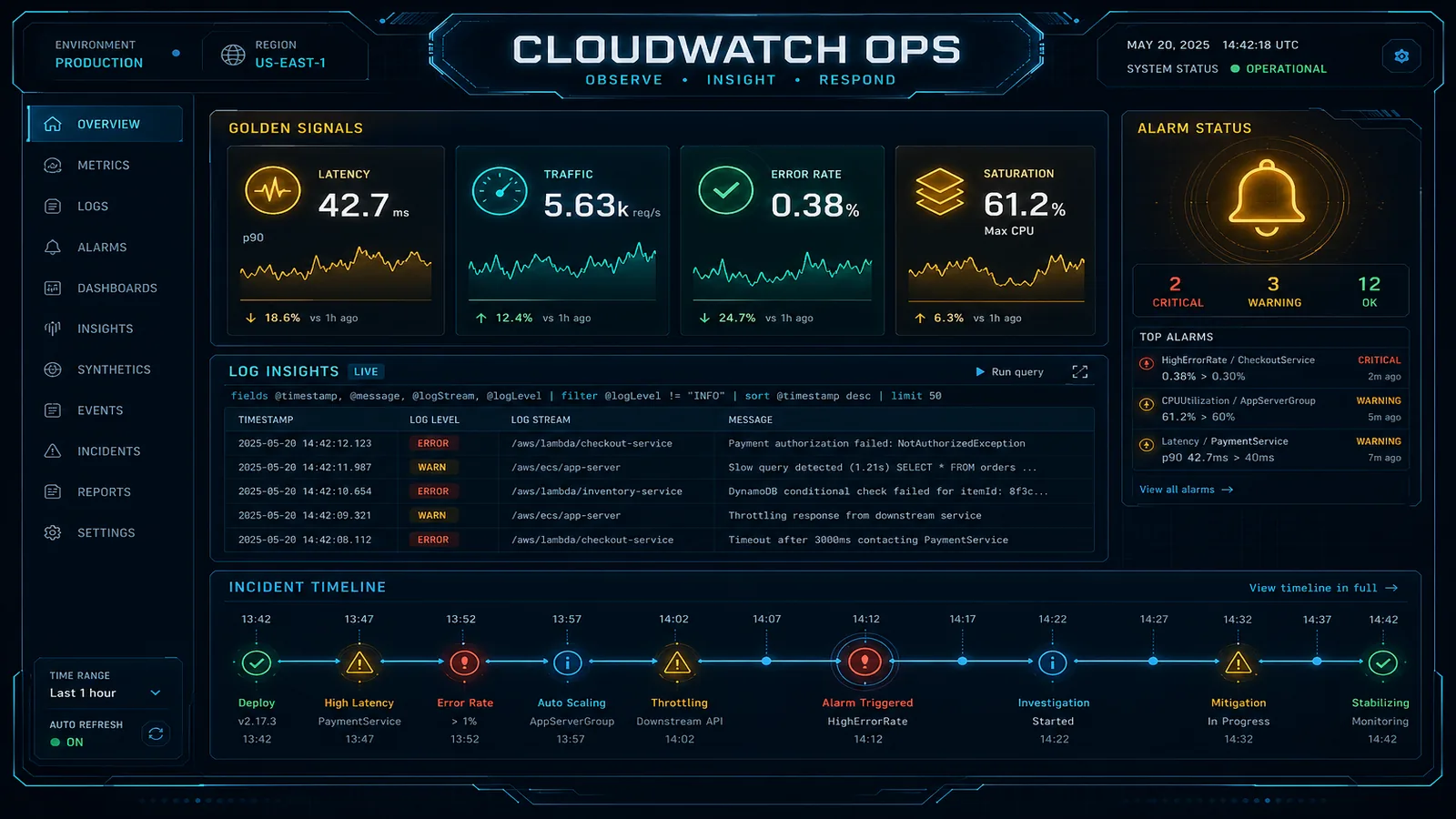
Log Aggregation and Intelligent Sampling with CloudWatch and OpenTelemetry
Ingesting every debug log to CloudWatch is how observability becomes a FinOps incident. Tail sampling with ADOT, Logs Insights, and Firehose to S3 for the long tail.